Big Data - Hive SQL
Hive SQL
1. Primitive types
- Types are associated with the columns in the tables. The following Primitive types are supported:
- Integers
- TINYINT—1 byte integer
- SMALLINT—2 byte integer
- INT—4 byte integer
- BIGINT—8 byte integer
- Boolean type
- BOOLEAN—TRUE/FALSE
- Floating point numbers
- FLOAT—single precision
- DOUBLE—Double precision
- Fixed point numbers
- DECIMAL—a fixed point value of user defined scale and precision
- String types
- STRING—sequence of characters in a specified character set
- VARCHAR—sequence of characters in a specified character set with a maximum length
- CHAR—sequence of characters in a specified character set with a defined length
- Date and time types
- TIMESTAMP — A date and time without a timezone (“LocalDateTime” semantics)
- TIMESTAMP WITH LOCAL TIME ZONE — A point in time measured down to nanoseconds (“Instant” semantics)
- DATE—a date
- Binary types
- BINARY—a sequence of bytes
The Types are organized in the following hierarchy (where the parent is a super type of all the children instances):
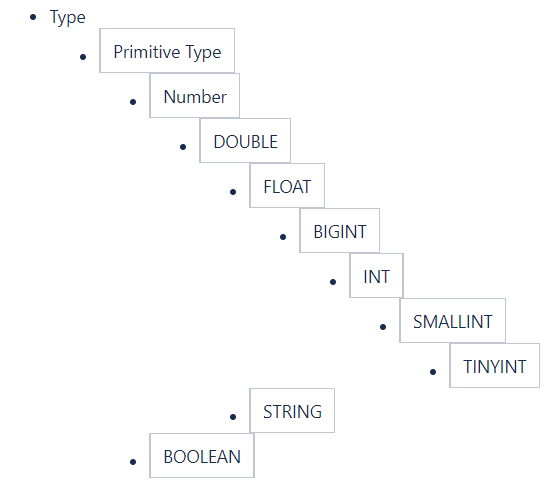
This type hierarchy defines how the types are implicitly converted in the query language. Implicit conversion is allowed for types from child to an ancestor. So when a query expression expects type1 and the data is of type2, type2 is implicitly converted to type1 if type1 is an ancestor of type2 in the type hierarchy. Note that the type hierarchy allows the implicit conversion of STRING to DOUBLE.
2. Type of tables
- Managed Table
- Hive will controls the lifecycle of data
- External Table
- Because the table is an external table, Hive doesn’t think it fully owns the data. Deleting the table will not delete the data, but the metadata information describing the table will be deleted.
- Convert table type
- From external table to managed table: alter table xxx set tblproperties(‘EXTERNAL’=’FALSE’);
- From managed table to external table: alter table xxx set tblproperties(‘EXTERNAL’=’TRUE’);
- Partition Table
- The partition table actually corresponds to an independent folder on the HDFS file system, under which all the data files of the partition are located
- The partition table in Hive actually means the partition of folder
3. Sort
(1) Order By
- Global sort, a Reducer. Apply to the final result.
- Can specify “ASC” ascend or “DESC” descend.
- Can apply to multi columns: order by col1, col2
(2) Sort By
- Sort internally by each Reducer, not for the global result set.
(3) Distribute By
- Similar to partition in MR, partition, combined with sort by.
- Hive demands to use ‘DISTRIBUTE BY’ before ‘SORT BY’.
(4) Cluster By
- When the distribute by and sorts by fields are the same, the cluster by method can be used.
- Has the functions of both ‘DISTRIBUTE BY’ and ‘SORT BY’, but can only apply to ASC.
- EX:
- select * from emp cluster by deptno;
- select *from emp distribute by deptno sort by deptno;
4. Partitioning vs Bucketing
(1) Partition table
- The partition table actually corresponds to an independent folder on the HDFS file system, under which all the data files of the partition are located.
- A partition in Hive is a sub-directory, which divides a large data set into smaller data sets according to business needs.
Example:
- Create partition table:
create table dept_partition( deptno int, dname string, loc string) partitioned by (month string) row format delimited fields terminated by '\t';
- Search in partition table:
select * from dept_partition where month='201709';
- Add partitions:
alter table dept_partition add partition(month='201706') ;
hive (default)> alter table dept_partition add partition(month='201705') partition(month='201704');
- Delete partitions:
alter table dept_partition drop partition (month='201704');
alter table dept_partition drop partition (month='201705'), partition (month='201706');
- Show partition number:
show partitions dept_partition;
(2) Bucketed table
- Partitioning is for data storage paths; bucketing is for data files.
Example:
- Create bucketed table:
create table stu_buck(id int, name string) clustered by(id) into 4 buckets row format delimited fields terminated by '\t';
- Show table structure:
desc formatted stu_buck;
- Normal query:
select * from stu_buck;
- Bucket sampling query:
- y must be a multiple or factor of the total number of buckets in the table. Hive decides the sampling ratio according to the size of y. For example, the table is divided into 4 copies in total. When y=2, the data of (4/2=) 2 buckets is extracted, and when y=8, the data of (4/8=) 1/2 buckets is extracted.
- x indicates which bucket to start extracting from. If multiple partitions need to be extracted, the subsequent partition number is the current partition number plus y. For example, the total number of buckets in a table is 4, and tablesample(bucket 1 out of 2) means that a total of (4/2=) 2 buckets of data are extracted, and the 1st(x) and 3rd(x+y) buckets are extracted. The data.
- x must be smaller than y, otherwise error will occur.
select * from stu_buck tablesample(bucket x out of y on id);
5. Useful Functions
(1) NVL: replace for NULL value
- nvl(string1, replace_with): if ‘string’ is NULL, then return with the value of ‘replace_with’
select nvl(comm,-1) from emp;replace with -1select nvl(comm,mgr) from emp;replace with another column value
(2) CASE WHEN: conditional expression
- case string1 when val then ret1 else ret2 end: if the value of ‘string1’ and ‘val’ match, then return ‘ret1’, else return ‘ret2’.
Example:
select dept_id, sum(case sex when '男' then 1 else 0 end) male_count, sum(case sex when '女' then 1 else 0 end) female_count from emp_sex group by dept_id;
(3) row to column functions
- CONCAT(string A/col, string B/col, …): Returns the result of the concatenation of the input strings, supports any number of input strings.
- CONCAT_WS(separator, str1, str2, …): Concatenates the strings end-to-end with the separator between them.
- Eg: concat_ws(‘,’, ‘A’, ‘B’, ‘C’) => ‘A,B,C’
- COLLECT_SET(col): The function only accepts basic data types, and its main function is to de-aggregate the value of a field to generate an array type field.
- COLLECT_LIST(col): Similar with collect_set, but will keep the duplicate values.
(4) column to tow functions
- EXPLODE(col): Split a complex array or map structure in one column of hive into multiple rows.
- LATER VIEW:
- Usage: LATER VIEW udft(expression) tableAlias AS columnAlias
- It is used with UDTFs such as split, explode, etc. It can split a column of data into multiple rows of data, and on this basis, the split data can be aggregated.
(5) Window functions
- Usage: SELECT
, (column_name) OVER ( ) FROM ; - column_name – column name of the table
- Aggregate – Any aggregate function(s) like COUNT, AVG, MIN, MAX
- Windowing specification – It includes following:
- PARTITION BY – Takes a column(s) of the table as a reference.
- ORDER BY – Specified the Order of column(s) either Ascending or Descending.
- Frame – Specified the boundary of the frame by stat and end value. The boundary either be a type of RANGE or ROW followed by PRECEDING, FOLLOWING and any value.
- These three (PARTITION, ORDER BY, and Window frame) are either be alone or together.
- WINDOWING Specification: In the windowing frame, you can define the subset of rows in which the windowing function will work. You can specify this subset using upper and lower boundary value using windowing specification.
- Syntax: ROW|RANGE BETWEEN
AND - UPPER EXPRESSION can have these 3 value:
- UNBOUNDED PRECEDING – It denotes window will start from the first row of the group/partition.
- CURRENT ROW – Window will start from the current row.
PRECEDING – Provide any specific row to start window
- LOWER EXPRESSION
- UNBOUNDED FOLLOWING – It means the window will end at the last row of the group/partition.
- CURRENT ROW – Window will end at the current row
FOLLOWING – Window will end at specific row
- Syntax: ROW|RANGE BETWEEN
- LEAD: It is an analytics function used to return the data from the next set of rows. By default, the lead is of 1 row and it will return NULL in case it exceeds the current window.
- LAG: It is the opposite of LEAD function, it returns the data from the previous set of data. By default lag is of 1 row and return NULL in case the lag for the current row is exceeded before the beginning of the window.
- FIRST_VALUE: This function returns the value from the first row in the window based on the clause and assigned to all the rows of the same group.
- LAST_VALUE: In reverse of FIRST_VALUE, it return the value from the last row in a window based on the clause and assigned to all the rows of the same group.
For more examples, refer to https://bigdataprogrammers.com/windowing-functions-in-hive/
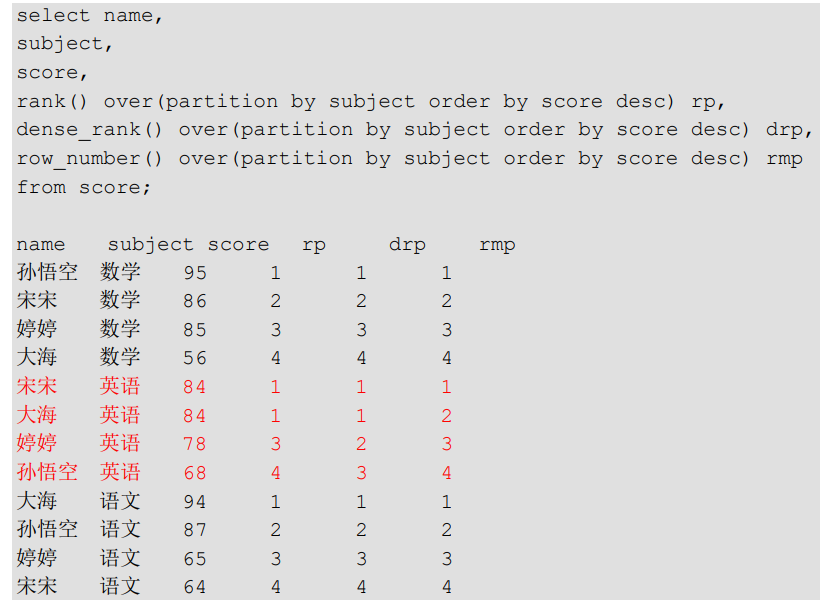
(6) RANK
- RANK(): It will repeat when the order is the same, the total will not change.
- DENSE_RANK(): Duplicates when the ordering is the same, the total will decrease.
- ROW_NUMBER(): Will be calculated in order.