Hadoop - 1. Introduction
Hadoop - 1. Introduction
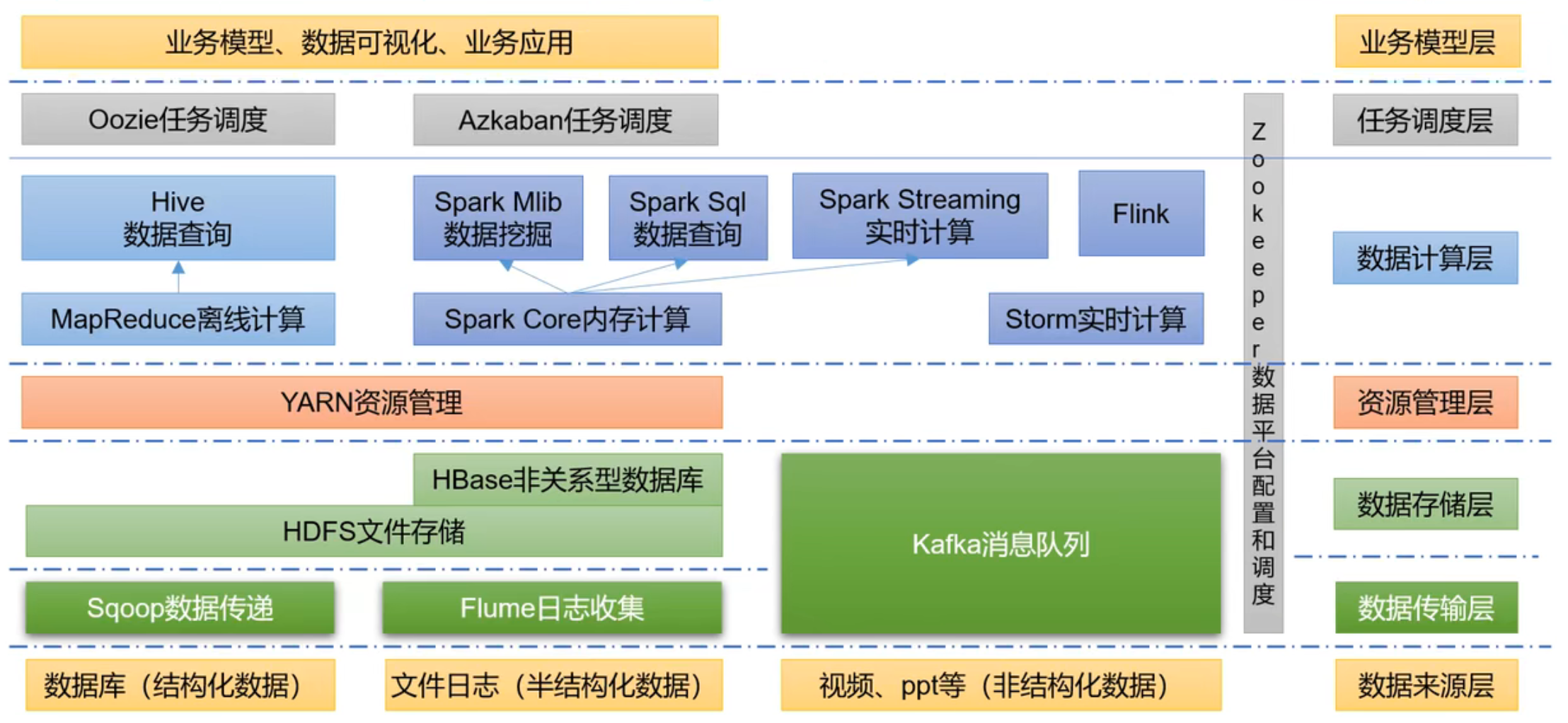
What’s Hadoop?
- Hadoop is a distributed system infrastructure developed by the Apache Foundation
- Mainly solve, the storage of massive data and the analysis and calculation of massive data
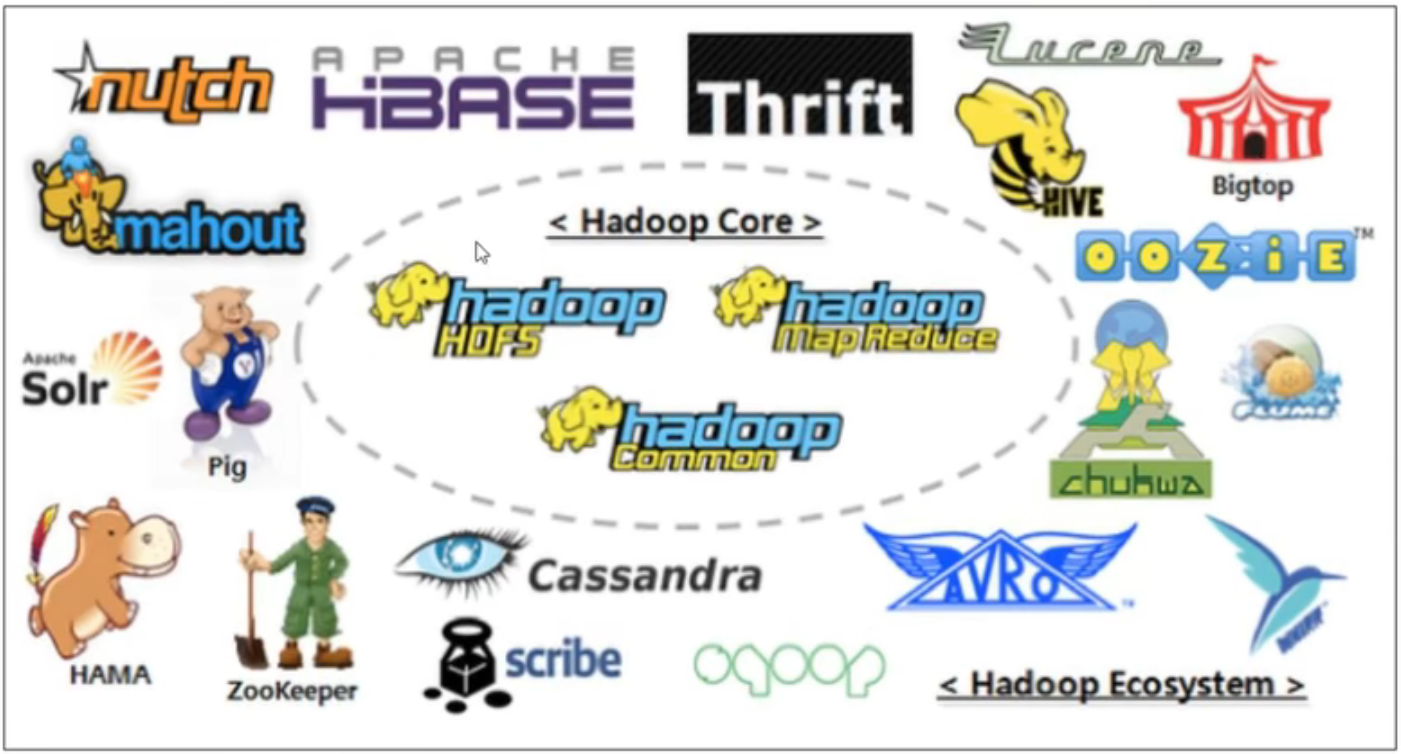
- Broadly speaking, Hadoop usually refers to a broader concept - the Hadoop ecosystem, including HBASE, HIVE, etc
What are the advantages of Hadoop?
- High reliability: The bottom layer of Hadoop maintains multiple copies of data, so even if a computing element or storage of Hadoop fails, it will not cause data loss
- High scalability: Distribute task data among clusters, which can easily scale to thousands of nodes
- Efficiency: Under the idea of MapReduce, Hadoop works in parallel to speed up task processing
- High fault tolerance: the ability to automatically reassign failed tasks
Components of Hadoop
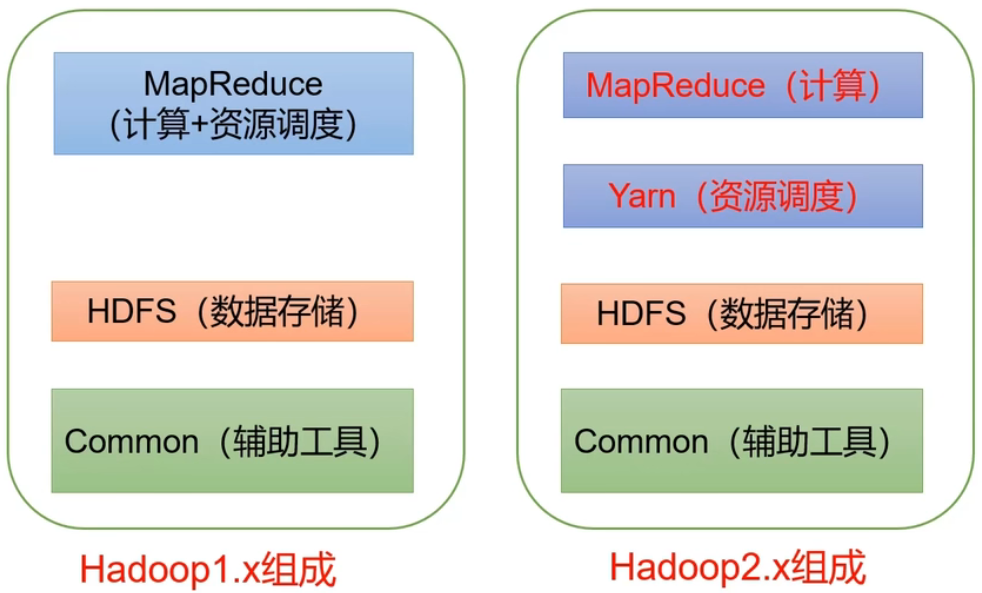
Hadoop3.x has no change in composition compared to Hadoop2.x
Overview of Hadoop Distributed File System (HDFS)
- NameNode (nn): Stores file metadata, such as file name, file directory structure, file attributes (generation time, number of replicas, file permissions), and the list of blocks for each file and the DataNode where the block resides, etc.
- DataNode (dn): Store file block data in the local file system, as well as checksums of the block data.
- Secondary NameNode (2nn): Backup NameNode metadata at regular intervals
Overview of Yet Another Resource Negotiator (YARN)
- Resource Manager (RM): Manage the entire cluster resources (memory, cpu, etc.)
- Node Manager (NM): Manage single node server resources
- Application Master (AM): Manage individual task
- Container: It is equivalent to an independent server, which encapsulates the resources needed to run tasks, such as memory, cpu, disk, network, etc.
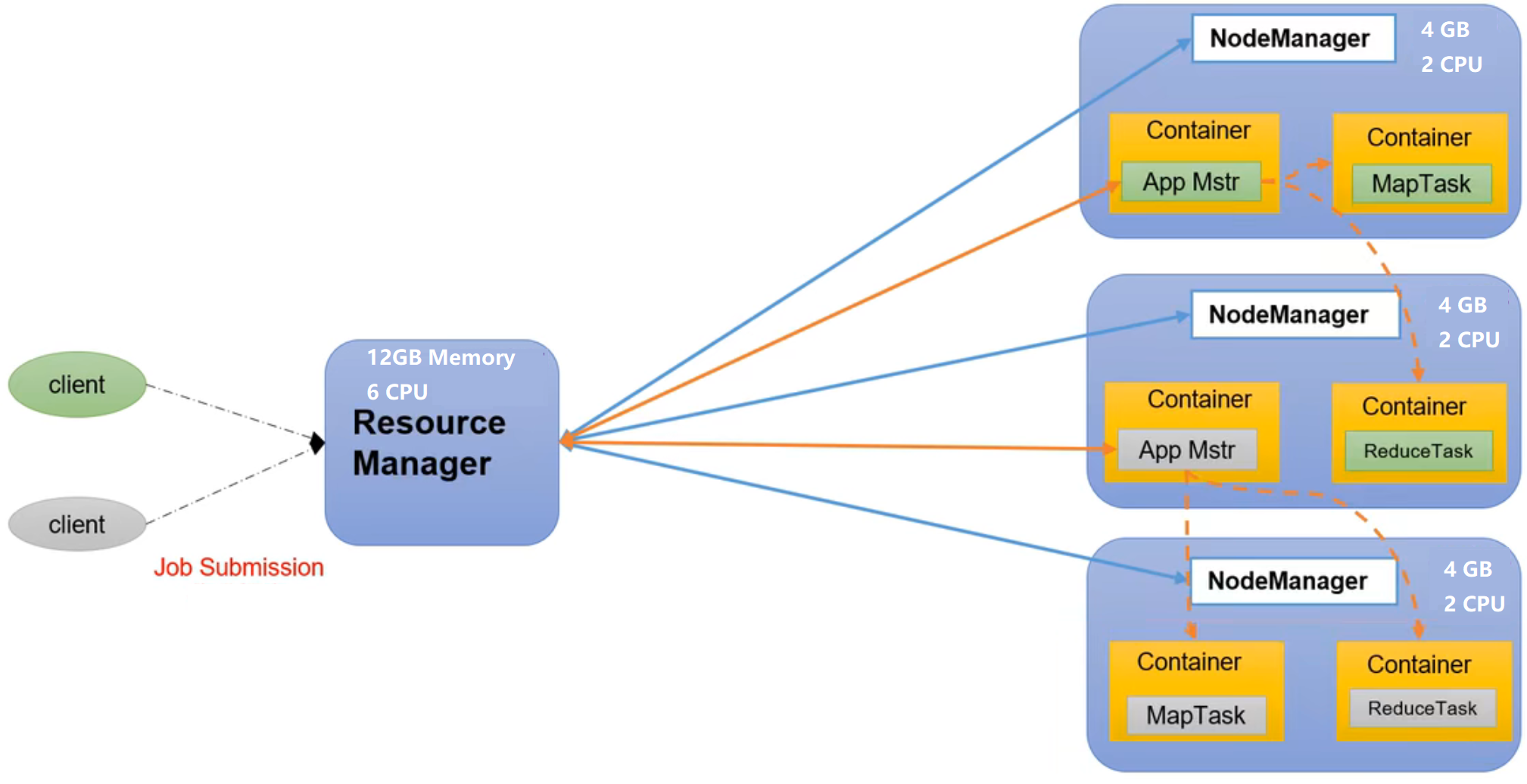
Reminder:
- Clients can be multiple
- Multiple Application Masters can run on the cluster
- There can be multiple Containers on each Node Manager
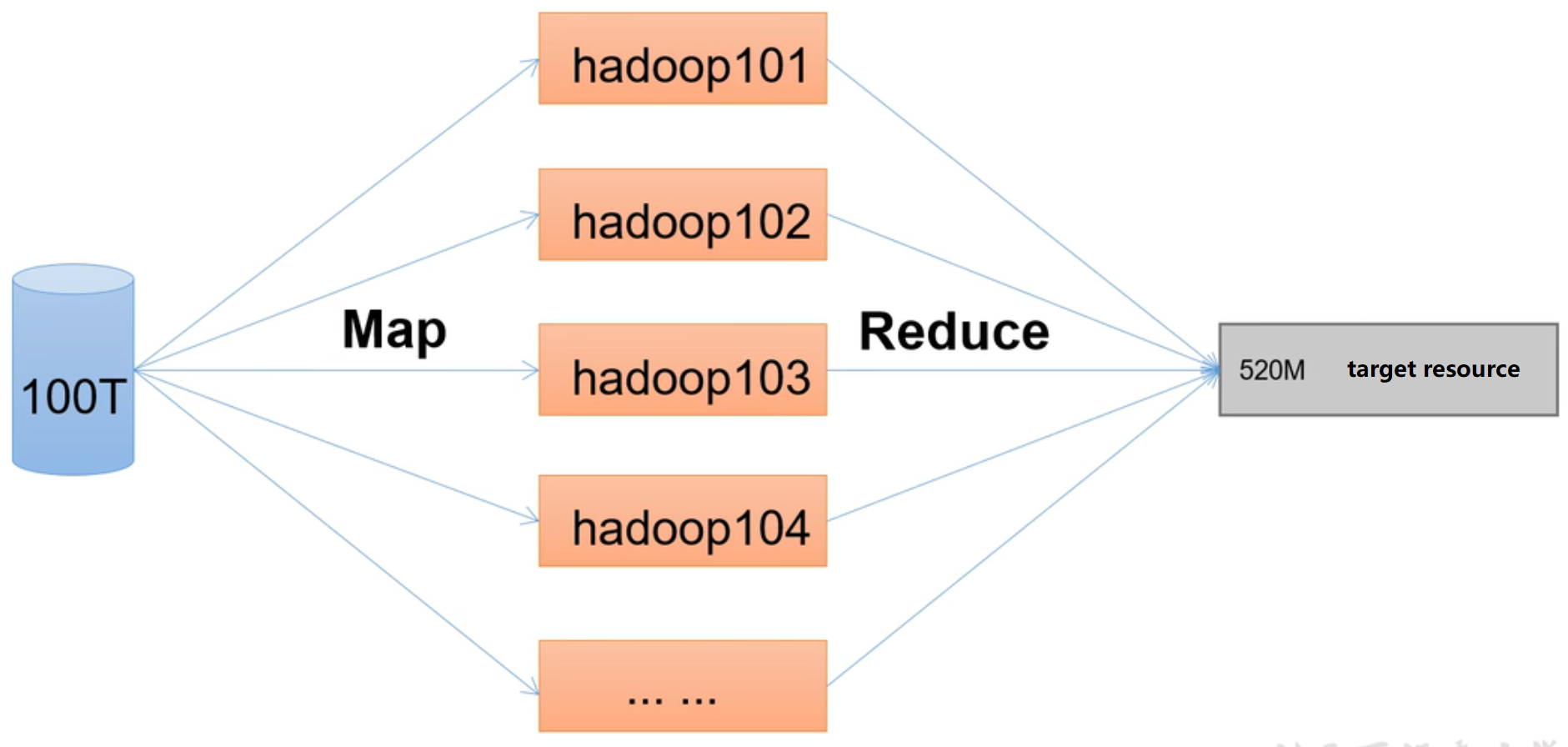
Overview of MapReduce
MapReduce divides the computing process into two stages: Map and Reduce
- Map processes the input data in parallel
- Reduce summarizes the results of Map
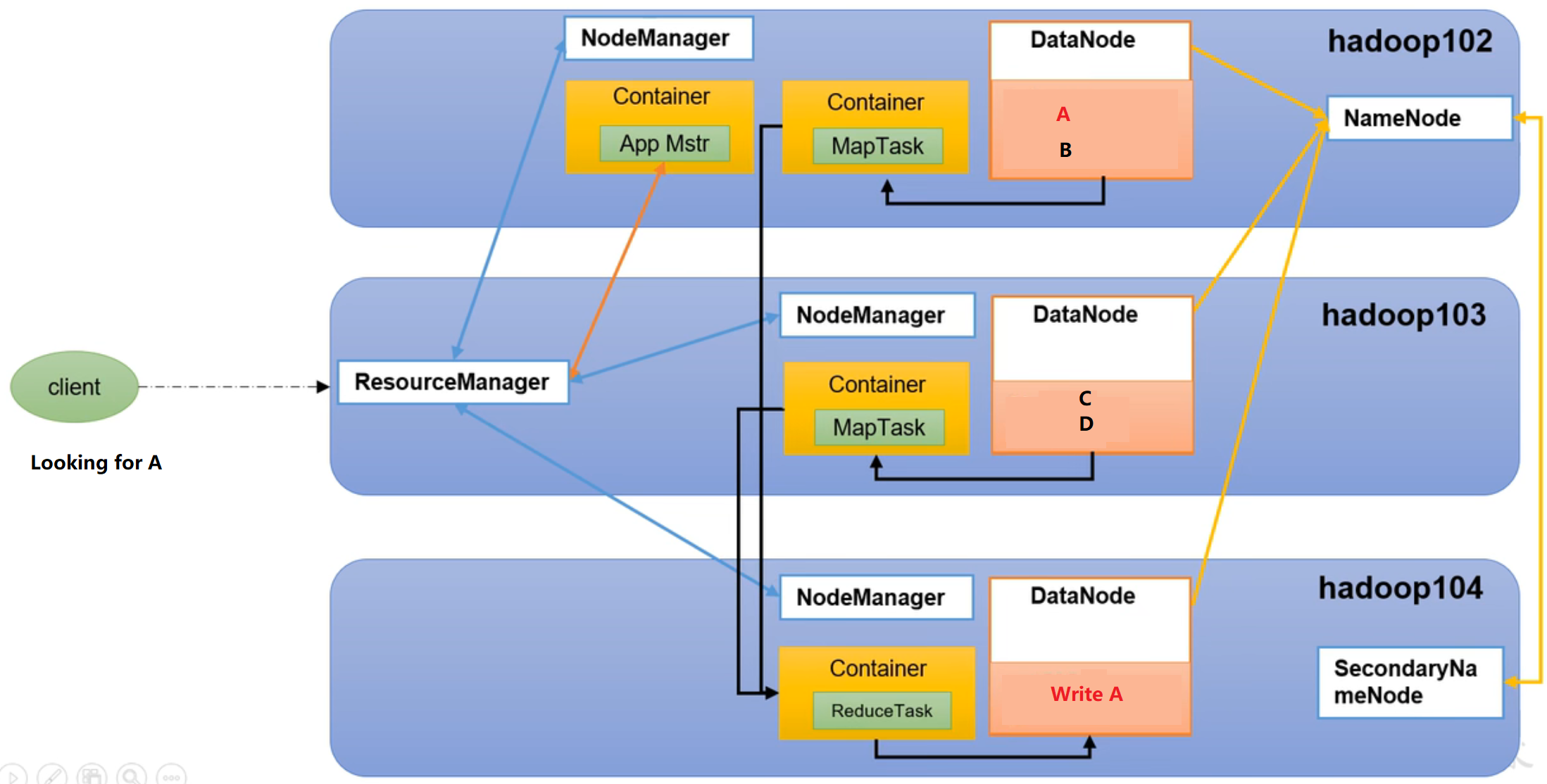
Relationship Between HDFS, YARN and MapReduce
Technology Ecosystem